Product
오픈소스 분야를 선도하는 전문기업 그로윈
Product
오픈소스 분야를 선도하는 전문기업 그로윈
High Availability(HA)란 장애 발생 시에도 시스템이나 애플리케이션이 지속적으로 운영되도록 설계된 특성으로, 가용성을 극대화하고 다운타임을 최소화합니다.
주로 데이터 센터, 클라우드, 핵심 비즈니스 환경에서 활용됩니다.

서버가 복구될 때까지 업무 및 서비스 정지
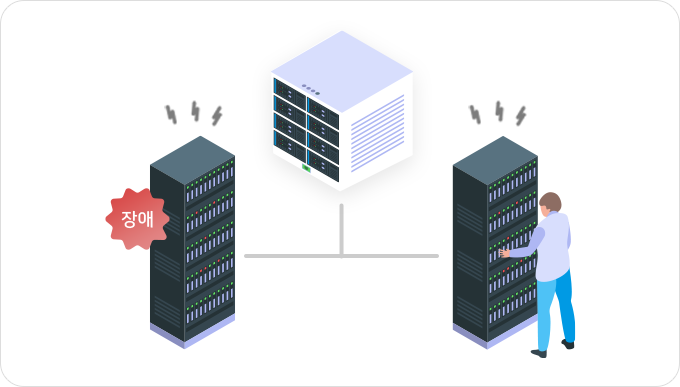
정상 스탠바이 서버로 업무 및 서비스를 인계




장애 발생 시 자동 전환(Failover)으로 서비스 중단 최소화
클러스터 또는 복제 구조로 무중단 운영 지원
단일 장애점(SPOF) 제거로 안정성 강화

Pacemaker: 노드 상태 모니터링 및 자원 자동 이전
MHA: 마스터 DB 장애 시 자동 슬레이브 승격 및 전환
MaxScale: 장애 감지 후 클라이언트 연결 자동 전환

Pacemaker: 리소스 상태를 실시간 관리 및 자동 확장
MHA: 장애 발생 시 복제 구조 전환으로 확장성 보장
MaxScale: 프록시 기반으로 다양한 구성에 유연하게 대응

MHA와 MaxScale로 복제 지연 최소화 및 안전 승격
공유 스토리지 또는 동기/비동기 복제로 정합성 유지
클러스터 환경에서 데이터 정확성과 일관성 확보

Pacemaker: 복잡한 클러스터 관리 자동화로 운영 부담 감소
MHA: 자동화된 장애 대응으로 운영 효율성 향상
MaxScale: GUI 및 API 기반 관리 도구로 편의성 제공
Copyright (C) GROWIN INC.
Designed by WebSite.co.kr